Object Oriented Selenium
Posted on Mar 22, 2015
Selenium is an awesome browser automation framework. It saves my team a ton of work on a daily basis. Even the name is incredibly clever:
The name Selenium comes from a joke made by Huggins in an email, mocking a competitor named Mercury, saying that you can cure mercury poisoning by taking selenium supplements. The others that received the email took the name and ran with it.
In this post, I will present my recommendation and best practices for building clean and maintainable Selenium code, based on what I’ve learned over the years.
Tip #1 - Abstract UI using PageObject pattern
Every UI framework out there emphasizes separation between UI and controller layers. In Selenium, this is done using the PageObject pattern. PageObject allows you to abstract away UI access from the rest of the code, resulting in clean, reusable, and most importantly - readable code. Instead of accessing divs and css, the code can focus on accessing content. Here’s what it looks like:
Instead of this
driver.get("http://github.com");
// click login button
WebElement loginButton = driver.findElement(By.cssSelector("a[href*='login']"));
loginButton.click();
// wait for page to load
By signInButtonLocator = By.cssSelector("input.btn");
new WebDriverWait(driver, 10).until(
ExpectedConditions.presenceOfElementLocated(signInButtonLocator)
);
// send username and password
driver.findElement(By.id("login_field")).sendKeys("nadavc");
driver.findElement(By.id("password")).sendKeys("ohrly");
// submit
WebElement signInButton = driver.findElement(signInButtonLocator);
signInButton.click();
// ..etc
Use this
new GitHubHome(driver)
.goToSignIn()
.withUsername("nadavc")
.withPassword("ohrly")
.signIn();
Tip #2 - Use @FindBy to remove boilerplate
PageObject is great for abstracting the UI, but the code is still a little verbose. Do you really need to call driver.findElement() for every UI element that is encapsulated by the PageObject? And what if not all elements are available during class creation?
Enter @FindBy - members annotated with @FindBy will be wrapped by a proxy that automatically looks up the element when called. You’ll need to call PageFactory.initElements() to set this up.
public class SignInPage extends SeleniumSegment {
@FindBy(id = "login_field")
private WebElement loginField;
@FindBy(id = "password")
private WebElement passwordField;
@FindBy(css = "input[value='Sign in']")
private WebElement signInButton;
// ... code omitted for brevity
}
Tip #3 - Split large PageObjects into smaller objects
Even with the PageObjects pattern, large pages may result in excessive amounts of code in a single class. Some would say that this is a variation of the God Object anti-pattern. To address this, my recommendation is to break large PageObjects into smaller PageObject components and embed them within the large one.
Tip #4 - Encapsulate repeated blocks into their own PageObjects
Most webpages contain repeated blocks that can be abstracted into a single PageObject class. Makes sense when you look at the following screenshot:
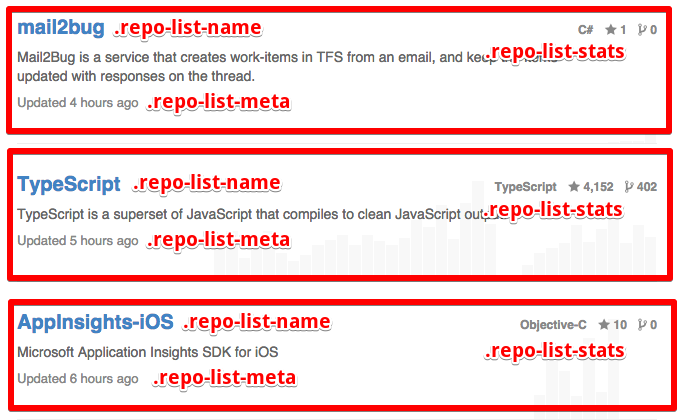
But how do you tell Selenium to confine @FindBy to search only for the right .repo-list-name? Luckily, Selenium supports the notion of context - whereas you get to define the root of @FindBy’s search. The trick is to call PageFactory.initElements() with a custom ElementLocatorFactory. See SearchSegment.java for a more concrete example.
Tip #5 - Use Selenium’s Wait mechanisms within PageObjects
The web is asynchronous by nature, and our Selenium code needs to adapt. Always put wait code within PageObjects, since these states belong in UI handling code and not anywhere else. Needless to say, Thread.sleep() is not the solution… use Selenium’s WebDriverWait (or its FluentWait facade).
Example code
In an effort to group all of these tips into working code, I built a simple GitHub scraper that uses Selenium to learn about Microsoft’s favorite open source languages. The source code is available through my GitHub account.
…and yes, I’m well aware that this could have been done using GitHub’s API and a few curl commands :)